4月15日,阿里云携手上海创智学院OpenMOSS团队正式开源了专为实时流式生成与端侧部署设计的极致轻量化模型MOSS-TTS-Nano。发布10天即狂揽53k+下载,Github Star数破2千!


MOSS-TTS系列开源模型由上海创智学院、复旦大学OpenMOSS团队及模思智能开发团队联合打造。该系列以极致轻量化设计突破算力瓶颈 —— 其中,MOSS-TTS-Nano作为代表模型,在阿里云国产算力生态的支持下,仅用0.1B 参数量即可实现 48kHz双声道高保真音质与20种语言覆盖。
依托阿里云及上海创智学院AI Infra团队打造的强大基础设施与国产算力支持,在此基础上学院AI Infra团队进行算力和底层平台的高度适配和优化,让MOSS-TTS系列模型整体在兼顾音质与推理效率方面取得突破,打破了“要速度就得牺牲音质”的传统困境,并持续推动实时流式语音交互能力向端侧设备落地。当前该系列模型已在 HuggingFace平台累计下载量突破89万次,充分体现了开源生态中的技术影响力。

MOSS-TTS-Nano不仅能在纯CPU环境下极速运行,更打破了过去轻量级TTS在音质和语种上的天花板:在仅0.1B(1亿)的极小参数规模下,原生实现了48kHz双声道(Stereo)的高保真输入输出,并一口气支持了全球20种语言!
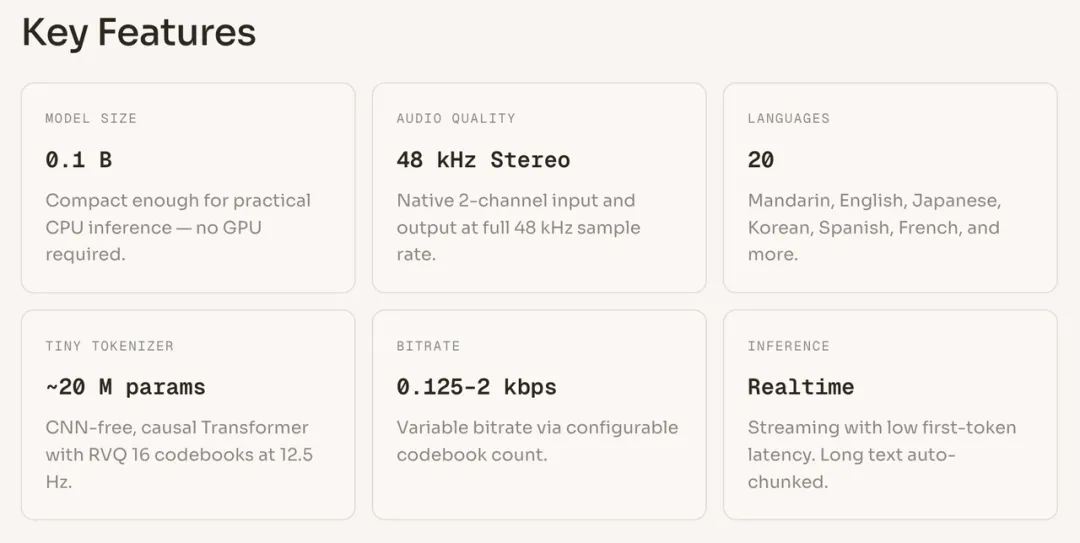
为什么语音交互需要一次“减负革命”?
当前主流的Zero-shot(零样本)开源TTS模型在实际落地时,普遍面临着一个难以调和的矛盾:要速度,就得牺牲音质;要音质,就跑不动。
第一,令人头疼的推理延迟。 为了生成几秒钟的高质量音频,大模型往往需要数秒的“思考(推理)”时间。这种延迟在对话机器人、虚拟数字人等需要“毫秒级响应”的场景中,会严重破坏用户的沉浸感。
第二,音质的天花板与空间感的缺失。 过去的开源零样本TTS模型,大多最高仅支持24kHz或16kHz的单声道音频。这种音频听起来总有一种干瘪的“电话音”或“机器味”,完全丧失了真实环境中的空间声场与高频细节。
第三,高昂的算力门槛。 动辄数十亿参数的模型,让单机部署、移动端应用或网页端实时交互面临巨大的显存与延迟压力。
第四,语种支持受限。 大多数轻量级模型仅支持中英双语,难以满足日益增长的出海业务与全球化沟通需求。
MOSS-TTS-Nano的回答是:用极致的架构创新,在“参数做减法”的同时,实现“音质与语种的全面升舱”。
下图展示了MOSS-TTS-Nano与主流TTS 统的参数规模对比,可以发现,当前大多数支持中英文的TTS系统参数规模集中在1B级别,而MOSS-TTS-Nano仅用0.1B参数量,就实现了同等级别的核心能力。
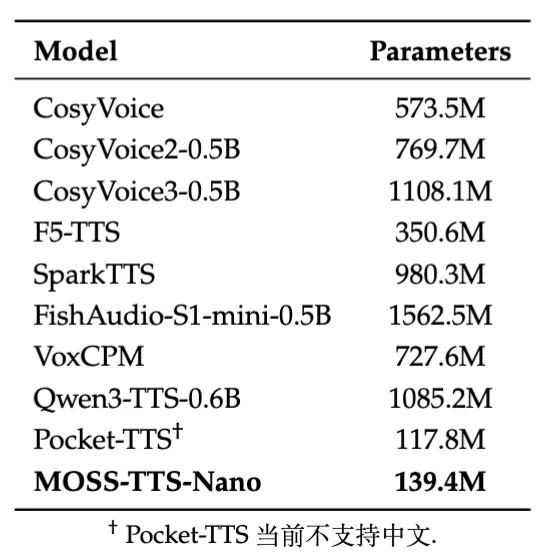
核心技术创新:小巧,却全能
极致轻量化的高性能音频Tokenizer,夯实高保真生成的底座
为了让仅仅0.1B的Nano模型拥有超越体型的录音棚级音质,阿里云平台携手上海创智学院OpenMOSS团队为其量身打造并同步开源了专属的底层声学基石 —— MOSS-Audio-Tokenizer-Nano。
作为MOSS-TTS-Nano模型的统一离散音频接口,这款Audio Tokenizer展现出了令人惊叹的工程美学与技术指标:
纯Transformer架构,彻底告别CNN:
它基于团队自研的Cat(Causal Audio Tokenizer with Transformer)架构构建。与过去依赖卷积神经网络(CNN)的传统Tokenizer不同,它完全由因果Transformer块组成,这使得其在处理长序列时具有更强的一致性和更低的时延。
20M极致微型,却打破“单声道”魔咒:
在这个动辄拼参数量的时代,MOSS-Audio-Tokenizer-Nano的参数量被极致压缩到了约20M。但正是这极其微小的体积,却原生攻克了48kHz超高采样率 以及 双声道(Stereo)立体声 的高保真压缩难题。它极大程度减少了高频细节的压缩损失,让声音彻底摆脱了干瘪感,保留了真实的呼吸声、环境混响与空间方位感。
高压缩比与变比特率:
支持将48KHz立体声音频压缩至12.5fps。基于16层RVQ机制,模型可在0.125-2kbps范围内实现灵活的码率调节,满足不同场景下的高保真重建需求。
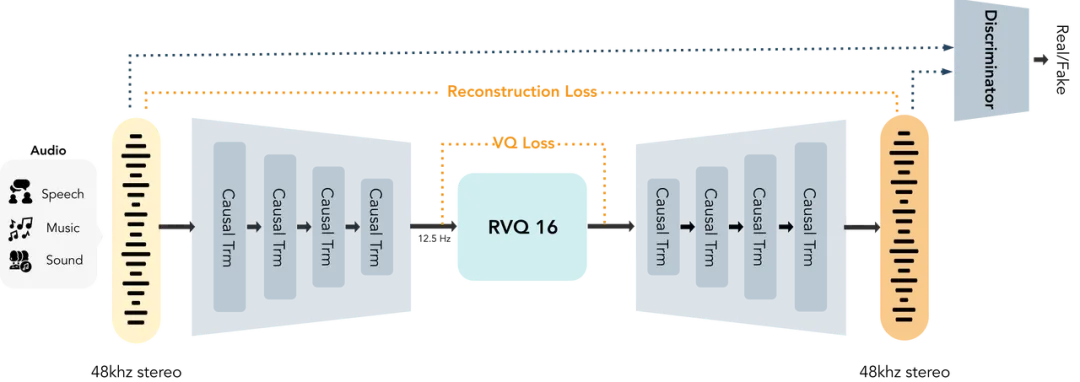
MOSS-Audio-Tokenizer-Nano 架构图
MOSS-TTS-Nano摒弃了对海量参数的盲目堆叠,采用纯自回归的Audio Tokenizer+LLM架构,并针对延迟和音频质量进行了底层重构,实现了在极小参数量下的卓越表现。
这一设计带来了四大核心优势:
毫秒级极低延迟:
彻底打破首字响应时间(RTF)的瓶颈。实测显示,MOSS-TTS-Nano能够在100毫秒内极速出声,天然适配语音助手的实时连续对话场景。
端侧友好,部署自由:
极致轻量的参数规模(仅0.1B参数),使其不仅能在单张消费级显卡上轻松运行,甚至在CPU或移动端边缘设备上也能实现流畅推理。
原生零样本音色克隆(Zero-Shot Cloning):
只需要短短3-5s的参考音频,MOSS-TTS-Nano就能精准捕捉说话人的音色特征和发音习惯,实现高保真的声音复刻。
细腻的情感与韵律感知:
突破了小模型“机械音”的魔咒。无论是中英混叠的自然衔接,还是抑扬顿挫的语气变化,Nano都能处理得游刃有余。
基于Audio-Tokenizer+LLM Backbone的端到端实时语音生成方案
有了极致强大的底层音频分词器,MOSS-TTS-Nano是如何在仅0.1B(100M)的极小参数下,实现毫秒级响应与录音棚音质的完美平衡的?
答案在于其精巧的全局与局部协同架构(Global & Local Transformer)。从下方架构图可以看出,MOSS-TTS-Nano采用了一种天然适配流式生成的端到端自回归范式,彻底重构了小模型的推理效率:
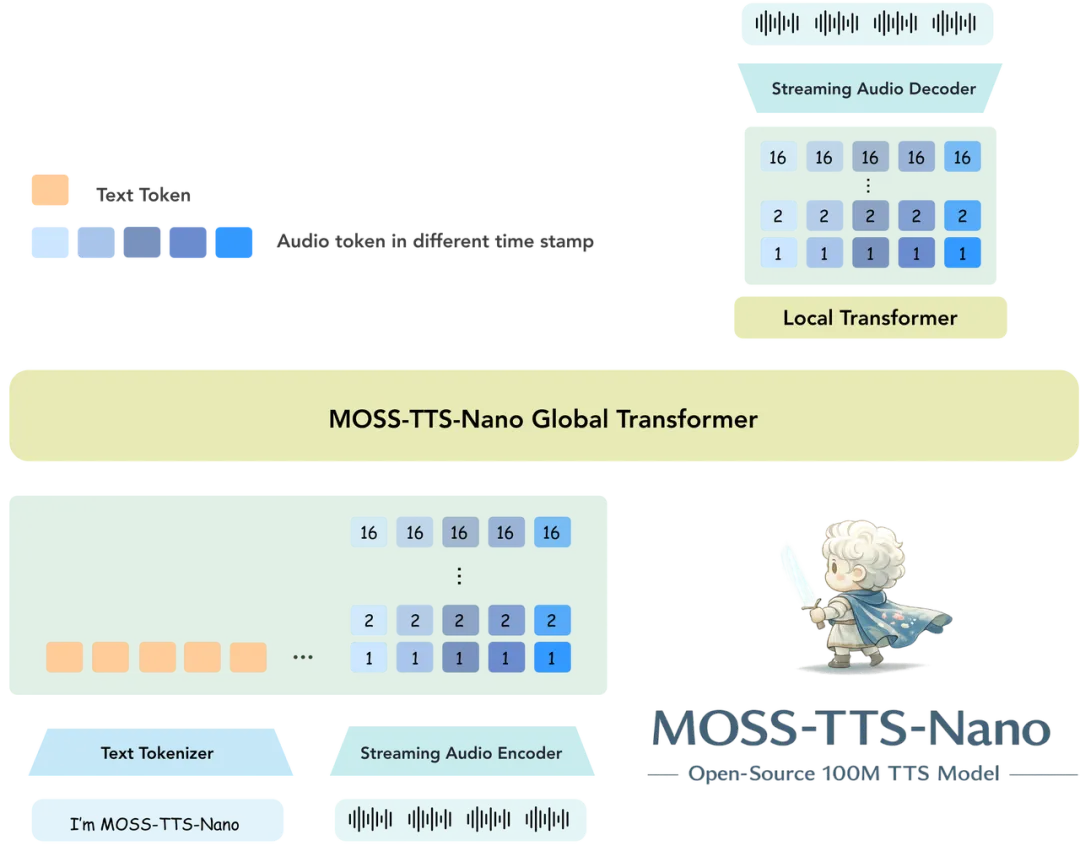
1. 统一的多模态输入表征 (Text & Audio Tokenizer):
模型打破了文本与声音的壁垒。输入的文本通过Text Tokenizer转化为文本Token;同时,提示/参考音频通过MOSS-Audio-Tokenizer-Nano的Streaming Audio Encoder极速压缩为携带时序信息的音频Token。文本与声音在输入端被统一为同一种“离散语言”,无缝融合。
2. Global Transformer统筹全局认知(大脑):
作为模型的核心枢纽,0.1B参数的MOSS-TTS-Nano Global Transformer扮演着“大脑”的角色。它负责处理跨模态的上下文,精准捕捉文本的语义逻辑,并深刻理解参考音频中的音色特质、情感走向与停顿韵律。
3. Local Transformer极速发射预测(嘴巴):
这是Nano能够实现“毫秒级流式低延迟”的核心秘诀!为了不让主干网络被繁重的音频细节拖垮,Nano引入了一个极其轻量的Local Transformer。全局网络只需指明“生成方向”(输出全局潜变量),局部网络便会接管工作,极速地逐层预测出1~16层的RVQ音频Token。这种“大统筹+小快跑”的机制,极大提升了吞吐量。
4. Streaming Audio Decoder实时流式解码:
随着Token被逐帧生成,MOSS-Audio-Tokenizer 的Streaming Audio Decoder同步介入,将这些离散信号瞬间还原为48kHz、双声道的高保真物理声波,实现真正的“边想边说”、“张口就来”。
面向智能时代,阿里云将继续携手上海创智学院,持续打通“顶尖人才培养—前沿科研突破—产业落地转化”的创新链路,以开放协同推动基础模型与交互智能不断演进,让更先进、更可用、更普惠的人工智能真正走进真实世界,服务人的创造、沟通与生产力提升。


