近日,计算机视觉国际大会ICCV2025公布论文评选结果,阿里云自主研发的最新技术成果《AirCache: Activating Inter-modal Relevancy KV Cache Compression for Efficient Vision-Language Model Inference》被大会录用。该研究聚焦视觉语言模型(VLMs)的高效推理难题,提出了一种新颖的AirCache技术,为多模态模型的高效推理提供了新的解决方案。
委员会评语:“AirCache作为专为视觉语言模型设计的KV缓存压缩方法,通过精准识别并保留最关键的视觉token,重构了多模态信息处理逻辑。论文最突出的价值在于通过多模型、多基准的强实证结果,充分验证了其在提升推理效率、降低存储开销方面的显著成效,为视觉语言模型的工程化落地提供了关键技术支撑。”

关于ICCV:ICCV是计算机视觉领域公认的国际顶级学术会议之一,被中国计算机学会(CCF)评为A类会议。该会议由IEEE与CVF共同主办,每两年举办一次,涵盖计算机视觉与模式识别的各类核心方向。2025年10月ICCV将于美国夏威夷举办,今年共收到11239篇有效投稿,最终录用2698篇论文,录用率为24%。
研究背景:破解大规模视觉语言模型推理的效率瓶颈
随着LVLMs的快速发展,其在处理多模态任务中展现出强大的推理和泛化能力。但面对真实场景,如处理高分辨率图像、多模态检索、知识增强、视频理解与分析等任务时,模型需要处理大量的视觉token以及长上下文输出,导致计算开销显著增加。这不仅带来了巨大的KV Cache存储需求,也对推理速度和显存消耗提出严峻挑战。
因此,如何在保证模型性能的前提下,提升推理效率、降低资源消耗,成为当前大规模视觉语言模型落地应用的一个关键问题。
目前业界主要通过视觉token剪枝和KV Cache压缩等方法来尝试解决这一瓶颈,但仍存在以下挑战:
• 视觉信息质量受损:传统的token剪枝方法在预填充阶段直接删除视觉token,导致视觉信息损失,严重影响模型性能。
• 压缩策略欠优化:现有的KV Cache压缩方法在评估视觉token重要性和分配压缩预算时,未能充分考虑多模态交互的特点,压缩效果不理想。
• 落地推广门槛高:部分方案为提升压缩提速效果,同时保持模型精度,需要针对模型进行结构修改,配合微调训练,但这需要花费大量的训练成本。
技术突破:AirCache跨模态关联激活与分层优化机制
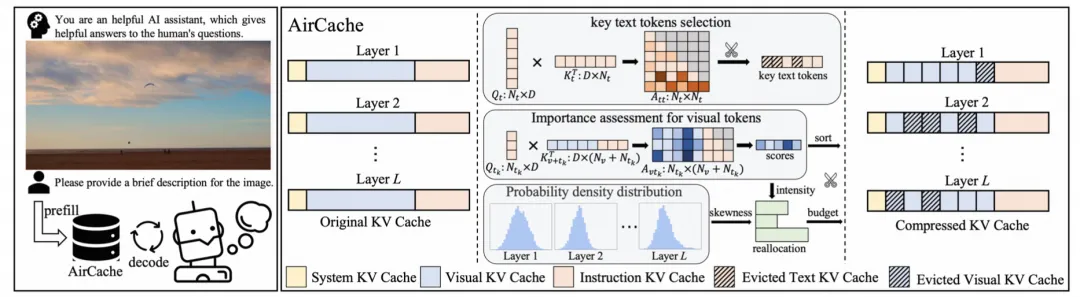
阿里云自主研发的AirCache技术,通过精准评估视觉token重要性和自适应压缩预算分配,显著提升了大规模视觉语言模型的推理效率:
1、Elite观察窗口:精准捕捉跨模态关联
AirCache创新性地提出了精英观察窗口机制,通过自注意力机制筛选指令文本token,精准识别关键文本,从而构建出更具代表性的观察窗口。这一机制改变了以往采用全部或连续局部文本token作为观察窗口的方式,有效提升了视觉token重要性评估的一致性与稳定性。
2、动态分层预算分配:基于重要性分布的智能优化
AirCache深入分析了不同层视觉token重要性分布的特征,提出了基于分布强度和偏度的动态分层预算分配策略。不同于均匀分配预算的传统方式,该策略从两个维度对各层的压缩预算进行量化:
• 重要性分布强度:通过计算所有视觉token重要性分数的总和,衡量该层对视觉信息的关注程度。关注程度越高的层,分配到的预算相对更多,以确保关键视觉信息得到保留。
• 重要性分布偏度:通过统计方法计算偏度值,评估各层视觉token重要性分布的集中程度。对于偏度值较高的层,说明其存在少数高重要性的视觉token,为这些层分配更多预算能够更好地保留关键信息,提升模型性能。
通过将这两个维度的指标进行归一化处理并融合,AirCache能够为各层动态分配最优的压缩预算,在保证模型性能的前提下,实现KV缓存的高效压缩。
3、跨模态冗余消除:保留10%缓存,实现近无损推理
AirCache通过精准的重要性评估和智能的预算分配,实现了对视觉KV缓存的高效压缩。实验结果表明,在保留仅10%视觉KV缓存的情况下,AirCache能够在多种LVLMs和基准测试中,实现与完整缓存相当的性能,平均性能下降幅度控制在1%以内。
• 在解码效率方面,AirCache展现出显著优势。在精度几乎无损情况下,其解码延迟降低幅度最高可达66%,吞吐量最高可提升192%。在不同批量大小和提示长度的输入场景下,均表现出稳定的加速效果。
• 与其他先进的KV缓存压缩方法相比,AirCache在压缩率和性能保持方面具有明显优势。当缓存保留率降低时,AirCache的性能优势愈发显著。例如,在仅保留1%视觉tokens的情况下,AirCache在Qwen2-VL-7B模型上的表现平均优于当前最优方法6.7%,展现出更强的鲁棒性和适应性。
• 另外,AirCache能够适配兼容多种主流的视觉语言大模型(VLMs),包括Qwen2-VL系列、LLaVA系列和InternVL系列等,无需对模型进行大规模修改和重新训练,具有良好的兼容性和可扩展性,且在各类多模态任务上均表现出色。
应用落地:多场景验证与行业价值创造
AirCache技术源于在服务各行业客户的海量视觉内容处理时,工程师高频遇到的性能瓶颈问题。该研究成果显著提升了多模态大模型在行业中的落地价值,如:
• 教育媒体行业:存在海量教材文档、教学视频、媒资图像/视频等内容理解,以及知识库加工和语料构建场景,AirCache加速多模态内容的解析与生成,大幅提升内容处理效率。
• 医疗能源行业:存在大量高分辨率、多序列医学影像理解分析场景,AirCache在保留关键视觉信息的前提下实现推理加速,提高诊断和异常发现的效率和准确性。
• 城市政务行业:面向城市治理的实时视频流处理、视频图像监控理解等场景,AirCache视频流分析技术能够有效提升视频处理效率,减少长视频对于显存的占用。
以长视频处理场景为例,与原生推理框架相比,AirCache将GPU KV Cache的显存占用降低80%, 单卡吞吐量大幅提升71%, 从而显著提升了可处理的上下文长度和整体效率。
目前,AirCache技术沉淀于阿里云百炼专属版产品体系,并与百炼专属版AI Stack一体机实现深度结合,持续构建软硬一体的技术优势,在教育、传媒、电力、医疗、制造、金融等多个行业领域发挥价值。


