阿里云论文“Tora:Trajectory-oriented Diffusion Transformer for Video Generation”被国际计算机视觉与模式识别顶会CVPR长文录用。该大会被中国计算机学会(CCF)列为A类会议,将于2025年6月11日至15日在美国田纳西州纳什维尔召开。
在这篇论文中,阿里云分享了新一代轨迹可控的视频生成技术Tora,支持轨迹、文本和图像这三种模态的融合输入架构。该技术通过创新的运动控制架构,适配各时长、分辨率及宽高比的视频生成需求,支持直线、曲线及复合轨迹的智能解析,从而实现镜头调度、物体位移的精准规划。
事实上,在AI生成技术蓬勃发展的当下,不少视频生成模型的动态效果已接近“以假乱真”,然而不可否认的是,由于在准确度和指令遵循能力上仍有局限性,传统生成过程常类似于“抽卡”,存在动态效果不可控、多次试错的计算与时间成本高等痛点,更会让创作者的创意无法完美落地。
该项技术的突破,正是为了解决这类问题,使得AI视频创作,像动画制作一样,严格遵照轨迹执行,从"概率游戏"升级为"更确定性工程"。
目前,该视频生成技术Tora 已被阿里云“智作工坊”平台集成,并封装为标准工作流节点。用户在生成视频时只需增加一个运动轨迹,便可让视频更贴近于逼真效果,同时,“智作工坊”作为专门面向ToB领域的生图产品,支持API或H5形式的一键部署,方便企业将其高效集成至业务系统中,缩短开发周期。
图示:通过绘制运动轨迹,生成对应动态作品
在具体的技术实现上,Tora引入了两个新型运动处理模块:轨迹提取器(Trajectory Extractor)和运动引导融合器(Motion-guidance Fuser),用于将提供的轨迹编码为多级时空运动补丁(Motion Patches)。
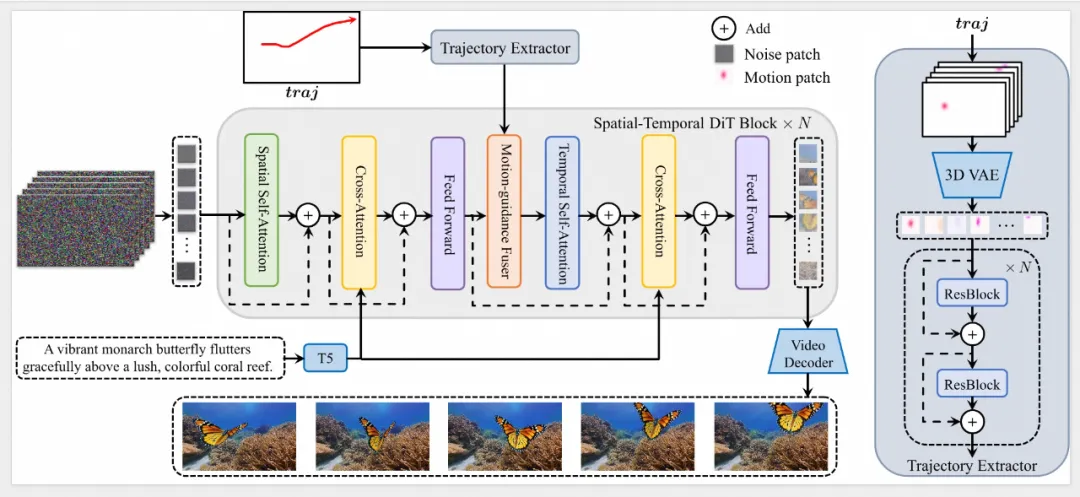
图示:Tora的整体架构(摘自论文)
这一方法符合DiT(Diffusion Transformer)的可扩展性,能够实现高分辨率、运动可控的视频创建,且持续时间更长。
• 轨迹提取器,采用3D运动变分自编码器(VAE),将轨迹向量嵌入到与视频补丁相同的潜在空间中,有效保留连续帧之间的运动信息,并使用堆叠的卷积层提取分层运动特征。
• 运动引导融合器,利用自适应归一化层,将这些多级运动条件无缝输入到相应的DiT块中,以确保视频生成始终遵循定义的轨迹。研究团队探索了多种融合架构的变体,其中自适应范数(Adaptive Norm)表现出最佳性能。
图示:基础模型生成的视频(左) VS Tora技术生成的视频(右)
Tora技术的代码已在Github全面开源,其模块化设计支持无缝迁移到各类Transformer视频模型。目前,集成Tora技术的阿里云“智作工坊”平台,已在文化传媒-影视制作、出版社/教育-数字作品等场景广泛应用,据使用者长期实测对比验证,与纯文字描述生成的视频相比,通过Tora的轨迹控制功能,其创作效率大幅提升。Tora让创作更高效、作品更有灵性。


